Googlebot is an automatic and always-on web crawling system that keeps Google’s index refreshed.
The website worldwidewebsize.com estimates Google’s index to be more than 62 billion web pages.
Google’s search index is “well over 100,000,000 gigabytes in size.”
Googlebot and variants (smartphones, news, images, etc.) have certain constraints for the frequency of JavaScript rendering or the size of the resources.
Google uses crawling constraints to protect its own crawling resources and systems.
For instance, if a news website refreshes the recommended articles every 15 seconds, Googlebot might start to skip the frequently refreshed sections – since they won’t be relevant or valid after 15 seconds.
Years ago, Google announced that it does not crawl or use resources bigger than 15 MB.
On June 28, 2022, Google republished this blog post by stating that it does not use the excess part of the resources after 15 MB for crawling.
To emphasize that it rarely happens, Google stated that the “median size of an HTML file is 500 times smaller” than 15 MB.
 Screenshot from the author, August 2022
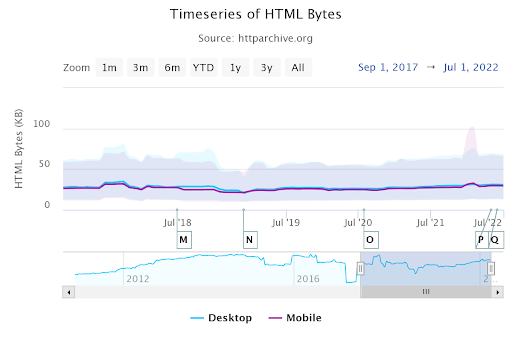
Screenshot from the author, August 2022Above, HTTPArchive.org shows the median desktop and mobile HTML file size. Thus, most websites do not have the problem of the 15 MB constraint for crawling.
But, the web is a big and chaotic place.
Understanding the nature of the 15 MB crawling limit and ways to analyze it is important for SEOs.
An image, video, or bug can cause crawling problems, and this lesser-known SEO information can help projects protect their organic search value.

Is 15 MB Googlebot Crawling Limit Only For HTML Documents?
No.
15 MB Googlebot crawling limit is for all indexable and crawlable documents, including Google Earth, Hancom Hanword (.hwp), OpenOffice text (.odt), and Rich Text Format (.rtf), or other Googlebot-supported file types.
Are Image And Video Sizes Summed With HTML Document?
No, every resource is evaluated separately by the 15 MB crawling limit.
If the HTML document is 14.99 MB, and the featured image of the HTML document is 14.99 MB again, they both will be crawled and used by Googlebot.
The HTML document’s size is not summed with the resources that are linked via HTML tags.
Does Inlined CSS, JS, Or Data URI Bloat HTML Document Size?
Yes, inlined CSS, JS, or the Data URI are counted and used in the HTML document size.
Thus, if the document exceeds 15 MB due to inlined resources and commands, it will affect the specific HTML document’s crawlability.
Does Google Stop Crawling The Resource If It Is Bigger Than 15 MB?
No, Google crawling systems do not stop crawling the resources that are bigger than the 15 MB limit.
They continue to fetch the file and use only the smaller part than the 15 MB.
For an image bigger than 15 MB, Googlebot can chunk the image until the 15 MB with the help of “content range.”
The Content-Range is a response header that helps Googlebot or other crawlers and requesters perform partial requests.
How To Audit The Resource Size Manually?
You can use Google Chrome Developer Tools to audit the resource size manually.
Follow the steps below on Google Chrome.
- Open a web page document via Google Chrome.
- Press F12.
- Go to the Network tab.
- Refresh the web page.
- Order the resources according to the Waterfall.
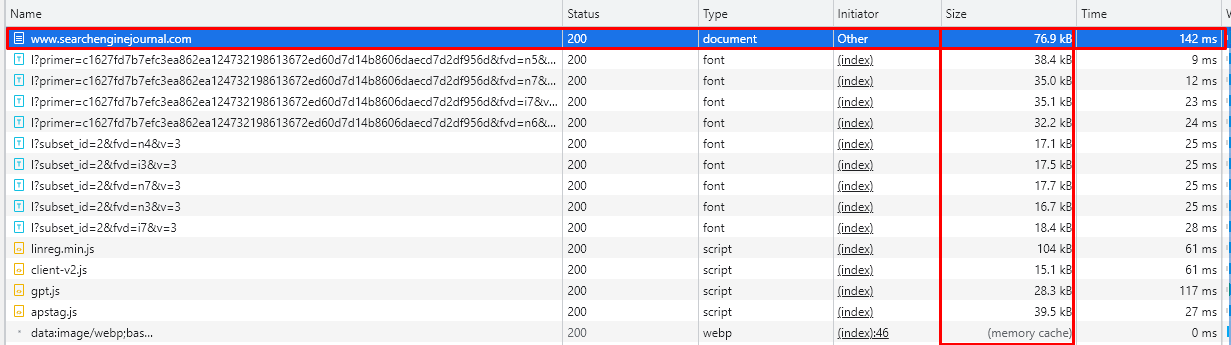
- Check the size column on the first row, which shows the HTML document’s size.
Below, you can see an example of a searchenginejournal.com homepage HTML document, which is bigger than 77 KB.
 Screenshot by author, August 2022
Screenshot by author, August 2022How To Audit The Resource Size Automatically And Bulk?
Use Python to audit the HTML document size automatically and in bulk. Advertools and Pandas are two useful Python Libraries to automate and scale SEO tasks.
Follow the instructions below.
- Import Advertools and Pandas.
- Collect all the URLs in the sitemap.
- Crawl all the URLs in the sitemap.
- Filter the URLs with their HTML Size.
import advertools as adv import pandas as pd df = adv.sitemap_to_df("https://www.holisticseo.digital/sitemap.xml") adv.crawl(df["loc"], output_file="output.jl", custom_settings={"LOG_FILE":"output_1.log"}) df = pd.read_json("output.jl", lines=True) df[["url", "size"]].sort_values(by="size", ascending=False)The code block above extracts the sitemap URLs and crawls them.
The last line of the code is only for creating a data frame with a descending order based on the sizes.
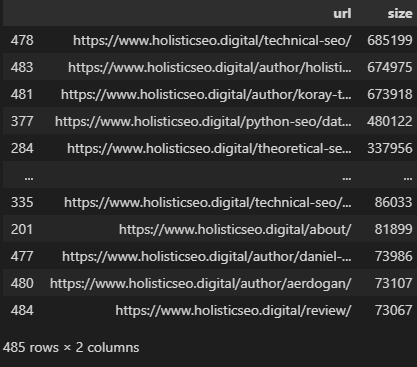 Image created by author, August 2022
Image created by author, August 2022You can see the sizes of HTML documents as above.
The biggest HTML document in this example is around 700 KB, which is a category page.
So, this website is safe for 15 MB constraints. But, we can check beyond this.
How To Check The Sizes of CSS And JS Resources?
Puppeteer is used to check the size of CSS and JS Resources.
Puppeteer is a NodeJS package to control Google Chrome with headless mode for browser automation and website tests.
Most SEO pros use Lighthouse or Page Speed Insights API for their performance tests. But, with the help of Puppeteer, every technical aspect and simulation can be analyzed.
Follow the code block below.
const puppeteer = require('puppeteer'); const XLSX = require("xlsx"); const path = require("path"); (async () => { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://www.holisticseo.digital'); console.log('Page loaded'); const perfEntries = JSON.parse( await page.evaluate(() => JSON.stringify(performance.getEntries())) ); console.log(perfEntries); const workSheetColumnName = [ "name", "transferSize", "encodedSize", "decodedSize" ] const urlObject = new URL("https://www.holisticseo.digital") const hostName = urlObject.hostname const domainName = hostName.replace("\www.|.com", ""); console.log(hostName) console.log(domainName) const workSheetName = "Users"; const filePath = `./${domainName}`; const userList = perfEntries; const exportPerfToExcel = (userList) => { const data = perfEntries.map(url => { return [url.name, url.transferSize, url.encodedBodySize, url. decodedBodySize]; }) const workBook = XLSX.utils.book_new(); const workSheetData = [ workSheetColumnName, ...data ] const workSheet = XLSX.utils.aoa_to_sheet(workSheetData); XLSX.utils.book_append_sheet(workBook, workSheet, workSheetName); XLSX.writeFile(workBook, path.resolve(filePath)); return true; } exportPerfToExcel(userList) //browser.close(); })();If you do not know JavaScript or didn’t finish any kind of Puppeteer tutorial, it might be a little harder for you to understand these code blocks. But, it is actually simple.
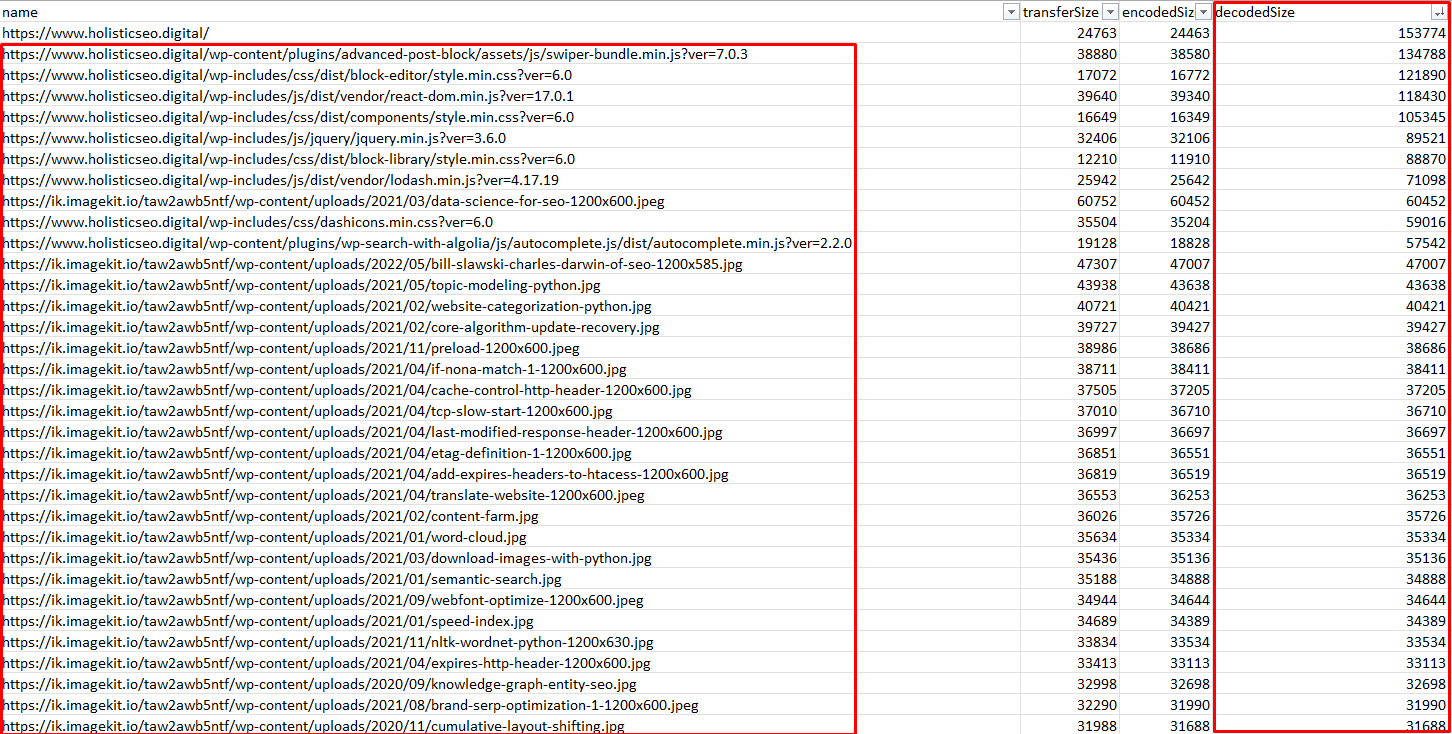
It basically opens a URL, takes all the resources, and gives their “transferSize”, “encodedSize”, and “decodedSize.”
In this example, “decodedSize” is the size that we need to focus on. Below, you can see the result in the form of an XLS file.
 Byte sizes of the resources from the website.
Byte sizes of the resources from the website.If you want to automate these processes for every URL again, you will need to use a for loop in the “await.page.goto()” command.
According to your preferences, you can put every web page into a different worksheet or attach it to the same worksheet by appending it.
Conclusion
The 15 MB of Googlebot crawling constraint is a rare possibility that will block your technical SEO processes for now, but HTTPArchive.org shows that the median video, image, and JavaScript sizes have increased in the last few years.
The median image size on the desktop has exceeded 1 MB.
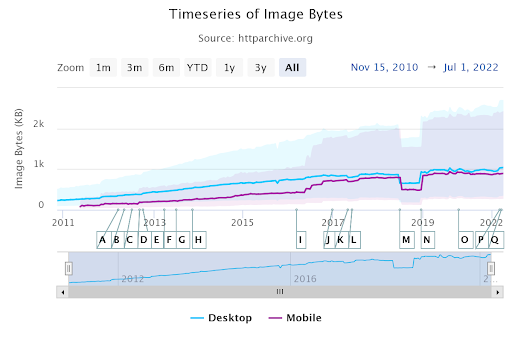 Screenshot by author, August 2022
Screenshot by author, August 2022The video bytes exceed 5 MB in total.
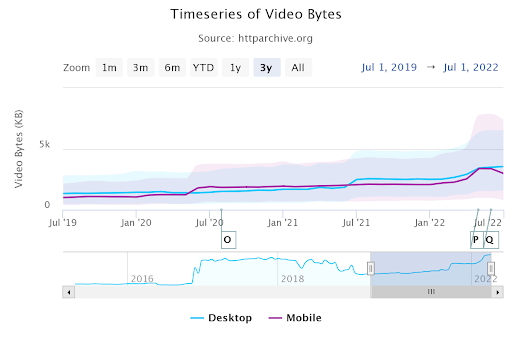 Screenshot by author, August 2022
Screenshot by author, August 2022In other words, from time to time, these resources – or some parts of these resources – might be skipped by Googlebot.
Thus, you should be able to control them automatically, with bulk methods to make time and not skip.
More resources:
Featured Image: BestForBest/Shutterstock